1-复杂的关联性研究
Date : [[2022-01-10_Mon]]
微信公众号 : 北野茶缸子
Tags : #统计/因果推断/孟德尔随机化
1-复杂的关联性研究
y = α + βx + ε
尝试通过简单回归,来判断x 与 y 的关系。
可是这样做,都不能排除潜在的(potential confounders,C)、无法测量的混杂因素(unmeasured confounders,U)的影响。
它们可能同时会对x 与y 产生影响。
举例来说,如果想要研究教育程度(接受教育年份)对未来收入(薪资)的影响,我们的确可以对二者进行回归,假定我们也的确发现了二者的相关性。
但此时,我们得到的相关系数beta,并不能用来评价这个教育程度对未来收入的影响。因为还有很多的混淆因素,并没有被考虑,比如家庭背景等等。
因此,这样得到的相关有非常大的“虚假关联”的可能。这里换个例子,比如说,我们发现冰淇淋的销量增长,溺水的人数也在增长,直觉上我们就可以发现有一些不对劲,如果你得到结论,“冰淇淋销量与溺水人数是正相关的”,我们不可以再卖冰淇淋了,那么这里就落入了虚假关联的圈套。比如说,这里“温度“就是一个混淆因素:温度升高,买冰淇淋的人多了,冰淇淋销量升高;人们同样为了解暑,去游泳的人多了,那么溺水的人数自然也就上升了。
此外,小时候在院子里种了一棵桃树,随着时间的推移,你的个子在长,桃树也在变高,如果说“我长桃树也长”是有关系的,那么同样也是被”虚假关联“给骗了。这里的混淆变量是什么呢?
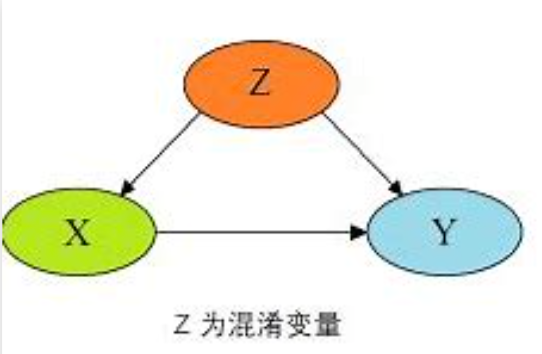
如果去探索医学科研中的“暴露”与“结局”之间的因果性呢?比如控制变量,比如广泛收集每个样本的各种暴露与结局?
然而,现实研究的案例,往往比上述案例要复杂。我们也未必能确定这些混淆因素的种类;另外,即便我们收集了这些混淆因素,我们也不便对它们控制变量。
那么我们该如何进行呢?
队列虽好,却是可望不可及的。而更加省时省力的病例对照研究,受限于其研究设计,只能得到相关系,而无法得到因果性。为了解决这一问题,统计学家们就设计了孟德尔随机化(Mendelian Randomization, MR)。 ——孟德尔随机化 | Mendelian randomization - Life·Intelligence - 博客园 (cnblogs.com)
Last updated